
LiveRamp Engineering’s global Site Reliability Engineering (SRE) team has recently been formally established as its own separate team within LiveRamp engineering’s Infrastructure Platoon, focused heavily on LiveRamp’s new flagship product, LiveRamp Safe Haven.
This is the second of a two-part series. The first blog was OS Patch Management As Code with VM Manager.
Initially, much of our efforts were focused on identifying manual tasks in order to allow us to begin optimizing and automating everything. One of the common points across all good SREs and DevOps engineers is that we have an almost hard-wired need to automate routine, repetitive tasks. We’d much prefer to spend our time working on bleeding-edge technology and implementing solutions to make systems run faster, more smoothly, and to put it simply, better.
This brings us to the point of today’s story—configuration management as code.
What’s that, I hear you say? “But why are you only getting around to this now?!” As with all new software projects, you tend to incur some tech debt as you’re starting from the basis of a minimum viable product (MVP). However, our systems have matured far beyond MVP stage, and we’re now in a position to start paying off that debt.
We’ve had our infrastructure-as-code defined for quite awhile, and it’s a pretty mature platform. However, what happens once your infrastructure is built? Up until recently, the only way for us to ensure that a server was configured appropriately was to have someone following a runbook to set it up manually for whatever role it was going to fulfill. Normally, this would fall on a member of global SRE, and as we mentioned previously, doing this kind of thing rather than tackling higher-impact issues tends to make us grumpy. So, once we actually had the capacity to do something about it, we did.
If you’ve ever spent any time looking into config management, you’re probably aware of the large number of tools available for it with Chef, Ansible, Puppet, and Salt being the biggest names. However, given that the vast majority of our estate is hosted on Kubernetes clusters, investing the time, effort, and money into a platform like this seemed like a little overkill. We may revisit this solution in the future, but for now, our needs are modest and don’t justify the overhead. Instead, we made the decision to go with the GCP-native VM Manager OS config offering, as it offers a platform-agnostic, lightweight management interface for both config management and patch management.
Another benefit of using OS config is that it works nicely with Terraform and allows us to expand our infrastructure-as-code platform to also handle the post-creation setup. Now, I’d love to show you some of the actual examples we’re using, but that’s not allowed, and since I want to stay in good standing with security and legal, I’m better off keeping it generic. So, instead of sharing actual code, I’ll share a quick, mocked-up example of what such a policy might look like:

Hypothetical example
The useful thing about this is that we can create modules for each of the policies we want to roll out, and can simply drop in a small module block like this at the project level.
Within the policy resource itself, we can set inclusion or exclusion labels to ensure we’re targeting exactly the right infrastructure we’re looking for. Then, as long as we’ve configured the right labels on our infrastructure resources, the policies will get rolled out automatically.
Having it scoped per-project means that if there’s something that we want to develop or test, we can configure the policy and roll it out to a non-production environment first, to ensure that it behaves as we’d expect. It also means that, for regions with different privacy laws etc., we have the flexibility to create separate policies for each set of circumstances.
So, I’ve shown you how we call the policy modules, but what does an OS config policy itself look like? This page gives a pretty decent overview, but it doesn’t really tell you what it should look like within Terraform. I have to admit, when I was first looking at this, I got tripped up a little, as there are a number of similarly named resources that relate to different things: one was the beta version, and the other was the general availability release.
So, if you’re looking to leverage this yourself, ensure that you’re looking for resources called “google_os_config_os_policy_assignment” rather than “google_os_config_guest_policies.” Admittedly, either name is a bit of a mouthful.
Once you’ve got them applied, they’ll appear within your GCP compute engine UI like this:
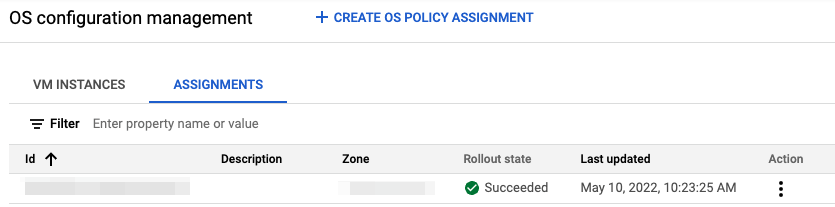
At a VM level, the list of policies applied to each VM looks like this:
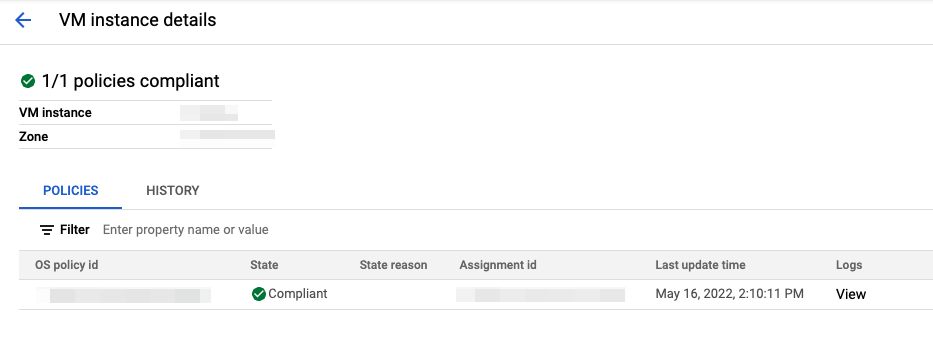
Ridiculously long Terraform resource names aside, having this all documented as code means that we can now start producing and leveraging these policy modules wherever we like. Which means manual configuration is no longer required, and no more having to touch production infrastructure. Most importantly, this removes any opportunity for someone to accidentally miss a step when following a runbook.
As a result, leveraging these policies will mean faster scale-up timeframes with more reliable configurations, and a known state for each and every one of our systems. We can also see exactly what has been configured and when, and with it being in source control, we can not only identify exactly which change may have caused an issue, but our peer review process means that these issues are far less likely to happen in the first place.
So, for each of those config runbooks, our next steps are to start turning them into reusable chunks of code. At the end of the day, this will mean that members of global SRE can get back to doing things like rolling out CI/CD pipelines-as-code, ensuring platform observability through our monitoring-as-code initiative (are you sensing an “as-code” theme yet?), and most importantly, coming up with the next winning hack-a-thon idea. Now, all we need is a confluence_to_terraform converter.
Actually, I think we’ve just found our next hack-a-thon idea!
LiveRamp is a data enablement platform designed by engineers, powered by big data, centered on privacy innovation, and integrated everywhere.
We enable an open web for everyone.
LiveRamp is hiring for fun and challenging engineering positions! Find more information about working at LiveRamp here.